* equal contribution
Links 👉 Github Code , ArXiv Paper , Cite BibTex
To operate effectively in the real world, agents should be able to act from high-dimensional raw sensory input such as images and achieve diverse goals across long time-horizons. Current deep reinforcement and imitation learning methods can learn directly from high-dimensional inputs but do not scale well to long-horizon tasks.
In contrast, classical graphical methods like A* search are able to solve long-horizon tasks, but assume that the state space is abstracted away from raw sensory input. Recent works have attempted to combine the strengths of deep learning and classical planning, however, dominant methods in this domain are still quite brittle and scale poorly with the size of the environment.
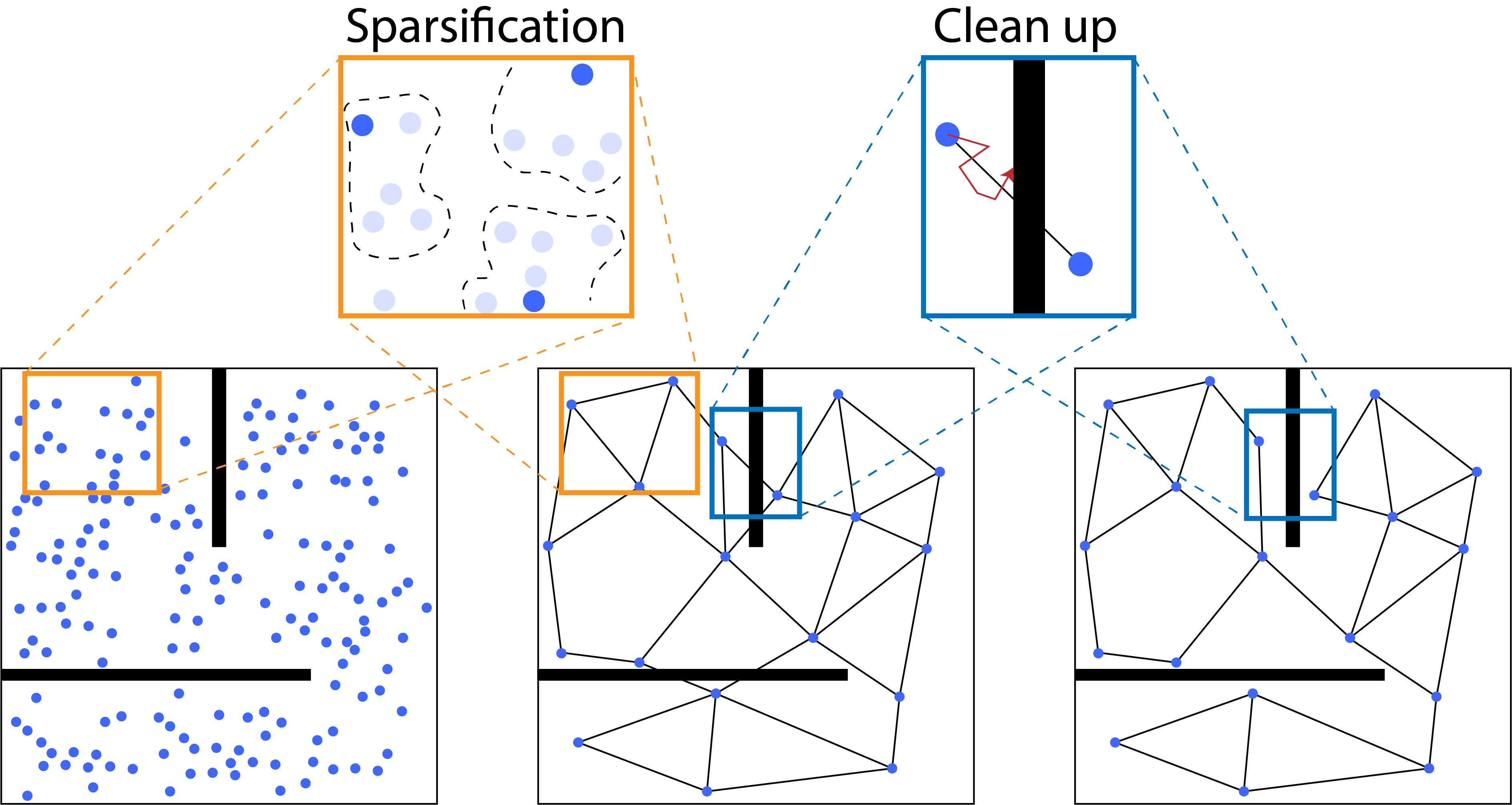
We introduce Sparse Graphical Memory (SGM), a new data structure that stores observations and feasible transitions in a sparse memory. SGM aggregates states according to a novel two-way consistency objective, adapting classic state aggregation criteria to goal-conditioned RL: two states are redundant when they are interchangeable both as goals and as starting states. We show that SGM significantly outperforms current state of the art methods on long horizon, sparse-reward visual navigation tasks.
Illustration of Sparse Graphical Memory (SGM) construction. As new observations are collected, they are either merged with the existing nodes of the graph or a new node is generated according to our two-way consistency criterion. Once the sparse graph is constructed, incorrect edges representing infeasible transitions between observations are corrected.
Short 3 minute video explaining SGM.
