* equal contribution
Links 👉 Github Code
, ArXiv Paper
, Cite BibTex
Media 📰 VentureBeat Article,
Twitter, BAIR blog
Learning from visual observations is a fundamental yet challenging problem in reinforcement learning (RL). Although algorithmic advancements combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) sample efficiency of learning and (b) generalization to new environments.
To this end, we present RAD: Reinforcement Learning with Augmented Data, a simple plug-and-play module that can enhance any RL algorithm. We show that data augmentations such as random crop, color jitter, patch cutout, and random convolutions can enable simple RL algorithms to match and even outperform complex state-of-the-art methods across common benchmarks in terms of data-efficiency, generalization, and wall-clock speed. We find that data diversity alone can make agents focus on meaningful information from high-dimensional observations without any changes to the reinforcement learning method.
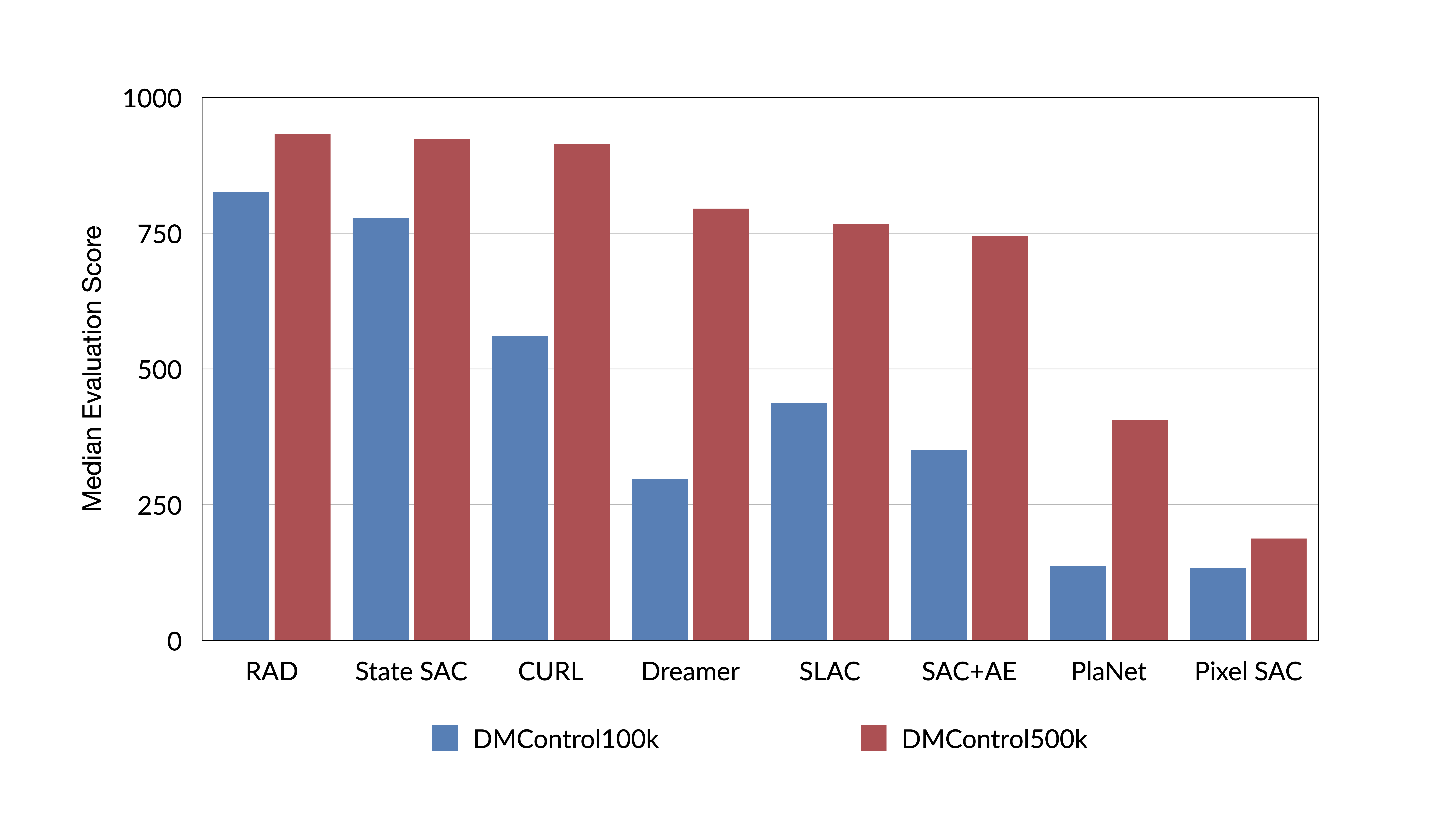
On the DeepMind Control Suite, we show that RAD is state-of-the-art in terms of data-efficiency and performance across 15 environments. We further demonstrate that RAD can significantly improve the test-time generalization on several OpenAI ProcGen benchmarks. Finally, our customized data augmentation modules enable faster wall-clock speed compared to competing RL techniques.
For pixel-based environments, we considered a diverse set of data augmentations and found that random cropping and translation alone enabled a simple RL algorithm (SAC) to achieve state-of-the-art performance, surpassing more complex algorithms. We showed similar results for state-based RL with a new augmentation - random amplitude scaling.
RAD outperformed previously competing baselines on the DeepMind control suite and, most suprisingly, matched and sometimes outperformed the state-based baseline where the RL agent had access to coordinate state. We also showed state-of-the-art results for generalization in pixel-based environments (ProcGen) and performance state-based RL (OpenAI gym).